Hadoop 2.8.5 集群搭建
教程环境:
CentOS 7、VMware 16、Hadoop - 2.8.5、JDK 1.8
主节点 - IP:192.168.10.10
从节点1 - IP:192.168.10.11
从节点2 - IP:192.168.10.12
注:未标注主节点或从节点配置的步骤,则所有节点都需配置
准备工作
- 虚拟机下安装 CentOS - 参考笔记 - 🌏 VMware Workstation Pro 安装 CentOS 7
- 静态IP地址及虚拟机联网设置 - 参考笔记 - 🌏 CentOS 7 静态IP地址设置
- 安装 JDK 环境 - 参考笔记 - 🌏 CentOS 7 安装 Java
- 🌏 Hadoop 安装包下载 - hadoop-2.8.5.tar.gz
- 时间同步 - 参考笔记 - 🌏 Linux 修改系统时间及时区
主机名修改
- 主节点
# hostnamectl set-hostname master
- 从节点1
# hostnamectl set-hostname slave01
- 从节点2
# hostnamectl set-hostname slave02
IP地址映射
- Linux 环境
# vim /etc/hosts
192.168.10.10 master
192.168.10.11 slave01
192.168.10.12 slave02

- Windows环境 - C:\Windows\System32\drivers\etc\hosts
- 可配可不配
192.168.10.10 master
192.168.10.11 slave01
192.168.10.12 slave02
上传 Hadoop
- 将
Hadoop安装包上传至,服务器,并解压
# tar -zxvf hadoop-2.8.5.tar.gz -C /usr/local/
- 修改文件夹名
# mv /usr/local/hadoop-2.8.5/ /usr/local/hadoop

修改环境变量
- 修改
/etc/profile,在末尾新增以下内容
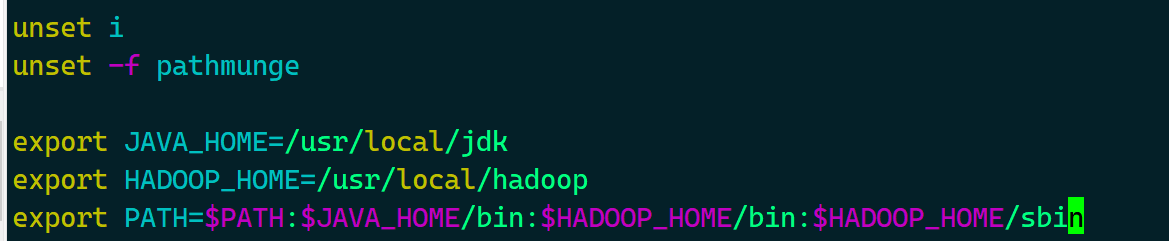
# vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 让profile文件生效
# source /etc/profile
Hadoop运行环境配置
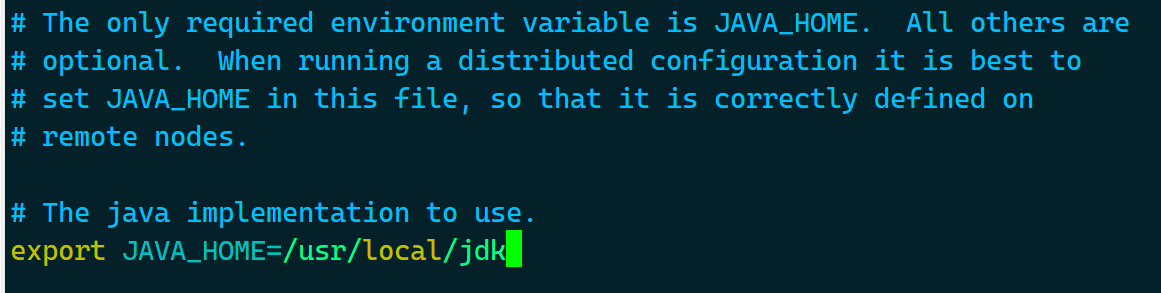
# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
- 修改
hadoop参数文件core-site.xml
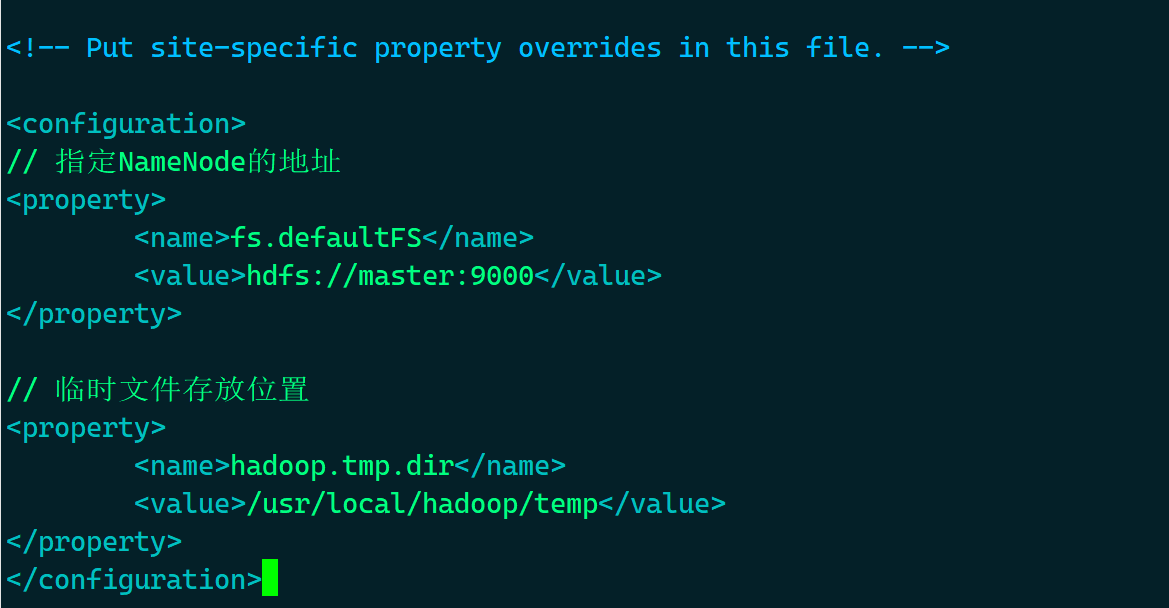
# vim /usr/local/hadoop/etc/hadoop/core-site.xml
- 在
<configuration></configuration>中,填入以下内容
// 指定NameNode的地址
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
// 临时文件存放位置
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/temp</value>
</property>
- 修改
hdfs-site.xml,目的:修改namenode和datenode存放路径,以及备份数量
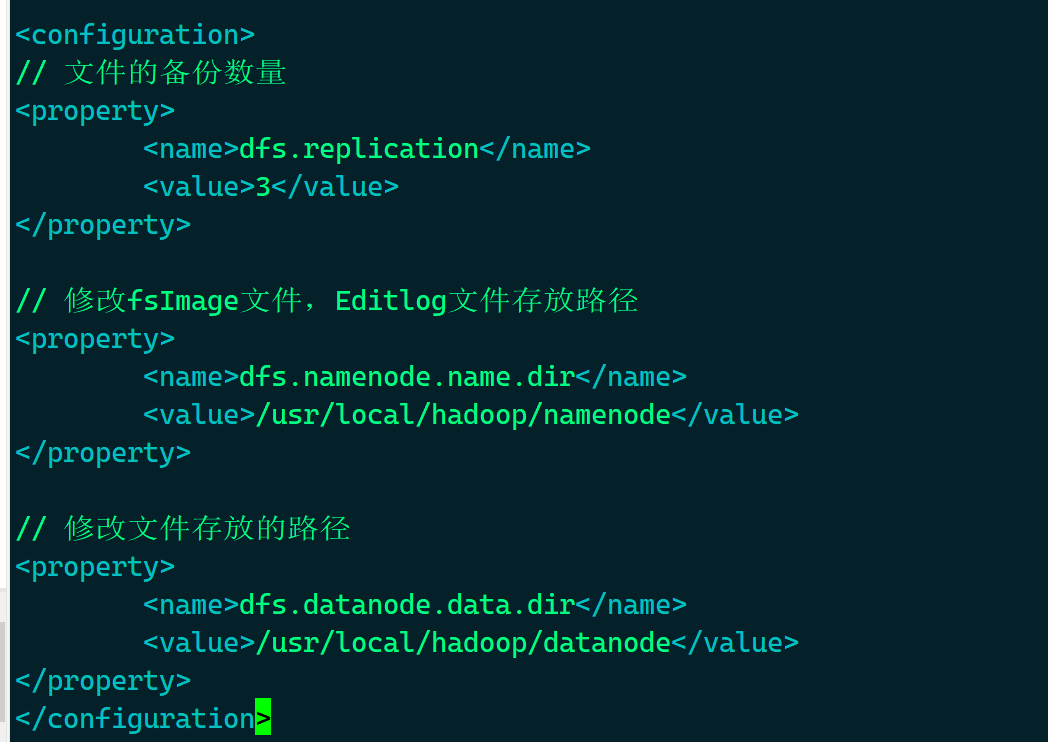
# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
- 在
<configuration></configuration>中,填入以下内容 - 主节点
// 文件的备份数量
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
// 修改fsImage文件,Editlog文件存放路径
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/namenode</value>
</property>
// 修改文件存放的路径
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/datanode</value>
</property>
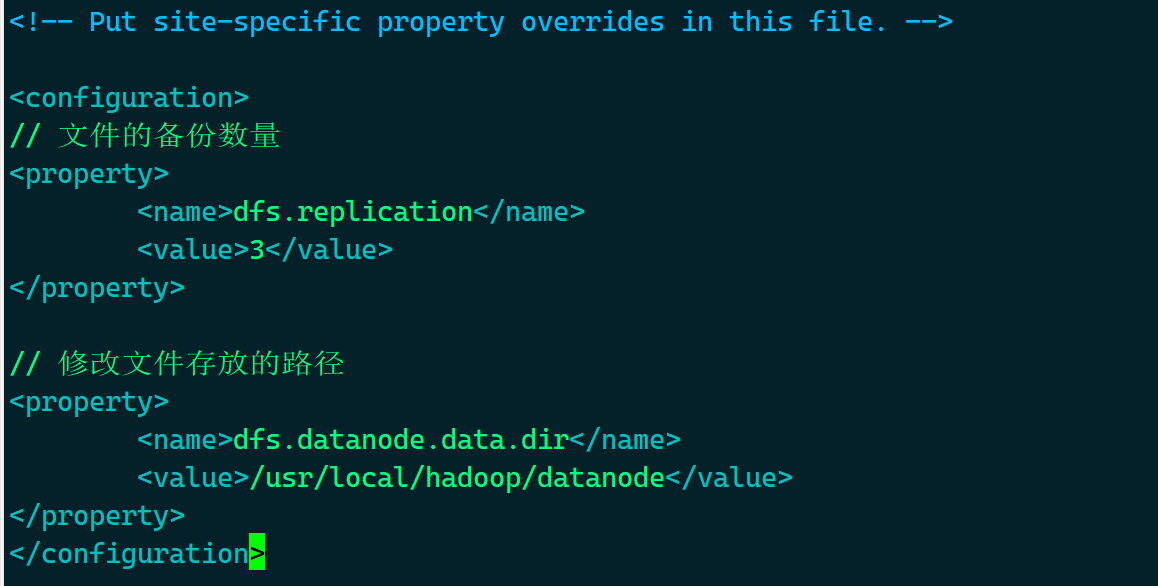
- 从节点
// 文件的备份数量
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
// 修改文件存放的路径
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/datanode</value>
</property>
- 修改
mapred-site.xml,用yarn集群来完成实现资源的分配
# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
mapred-site.xml不存在时
# cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
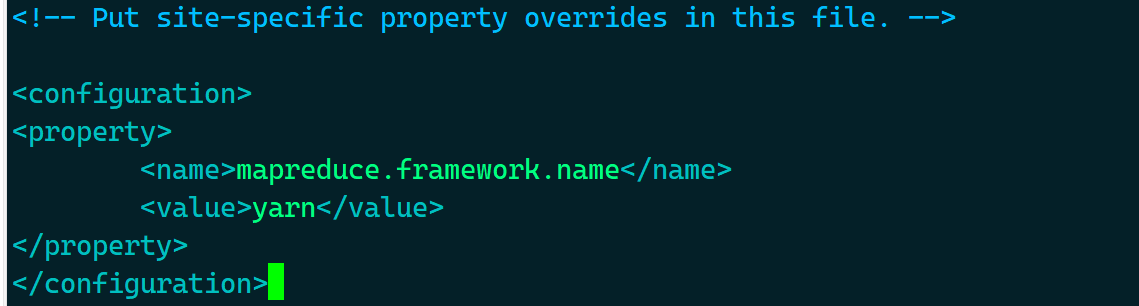
- 在
<configuration></configuration>中,填入以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 修改
yarn-site.xml
# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
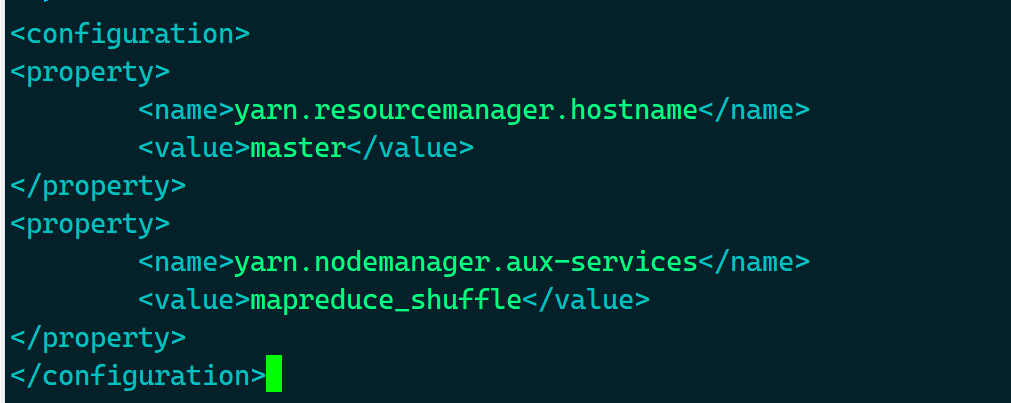
- 在
<configuration></configuration>中,填入以下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
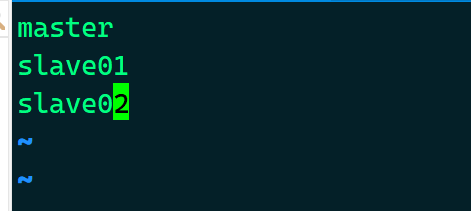
- 添加可启动的数据节点 - 只在 主节点 增加
# vim /usr/local/hadoop/etc/hadoop/slaves
master
slave01
slave02
初始化HDFS文件系统
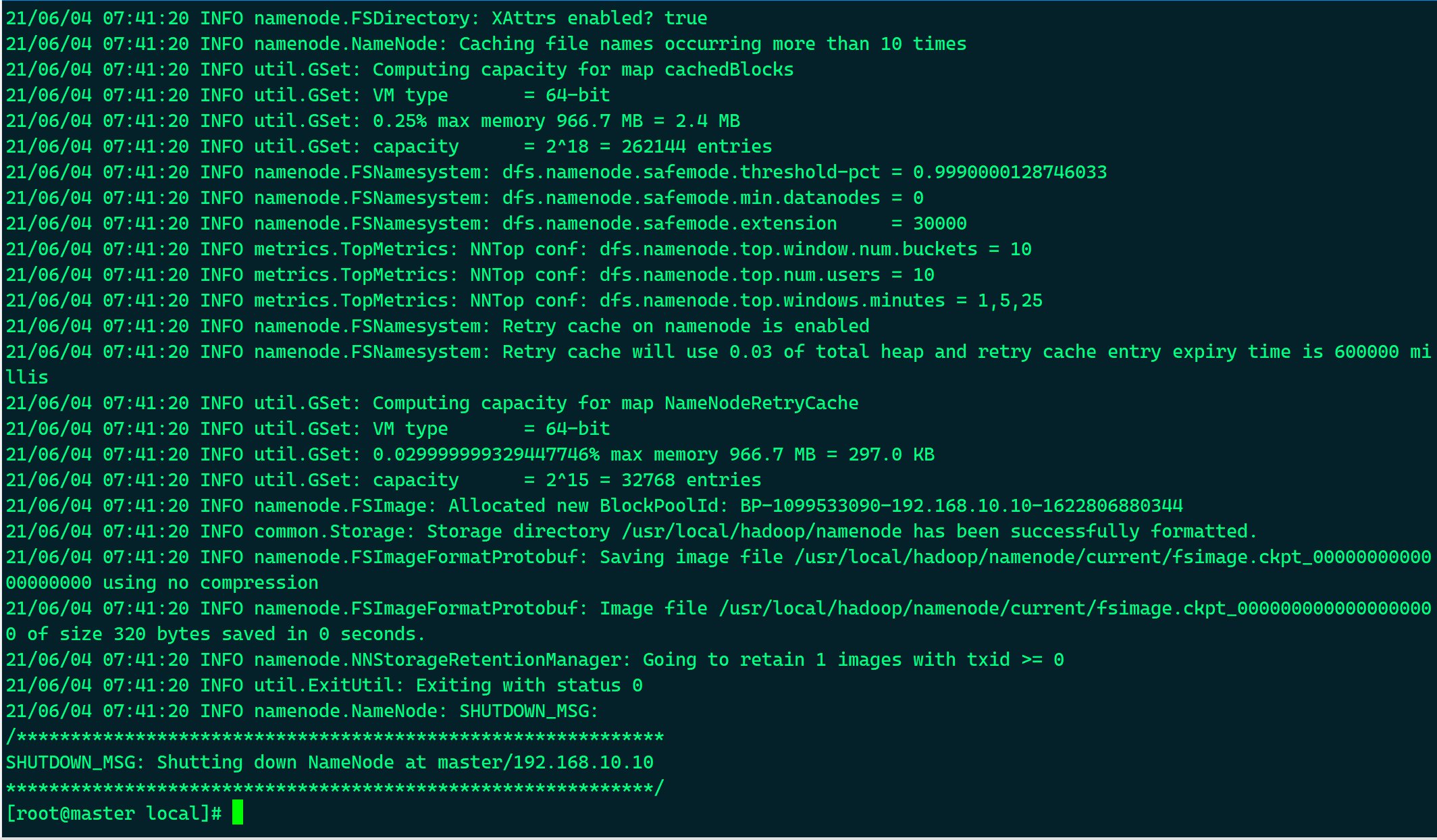
- 只在 主节点 执行
# hadoop namenode -format
SSH免密登录
# ssh master
# ssh slave01
# ssh slave02
# cd /root/.ssh
# rm -rf known_hosts
// ssh-keygen生成公私钥,期间只需进行回车操作
# ssh-keygen
# ssh-copy-id root@master
# ssh-copy-id root@slave01
# ssh-copy-id root@slave02
启停
- 启动
# start-all.sh
- 停止
# stop-all.sh
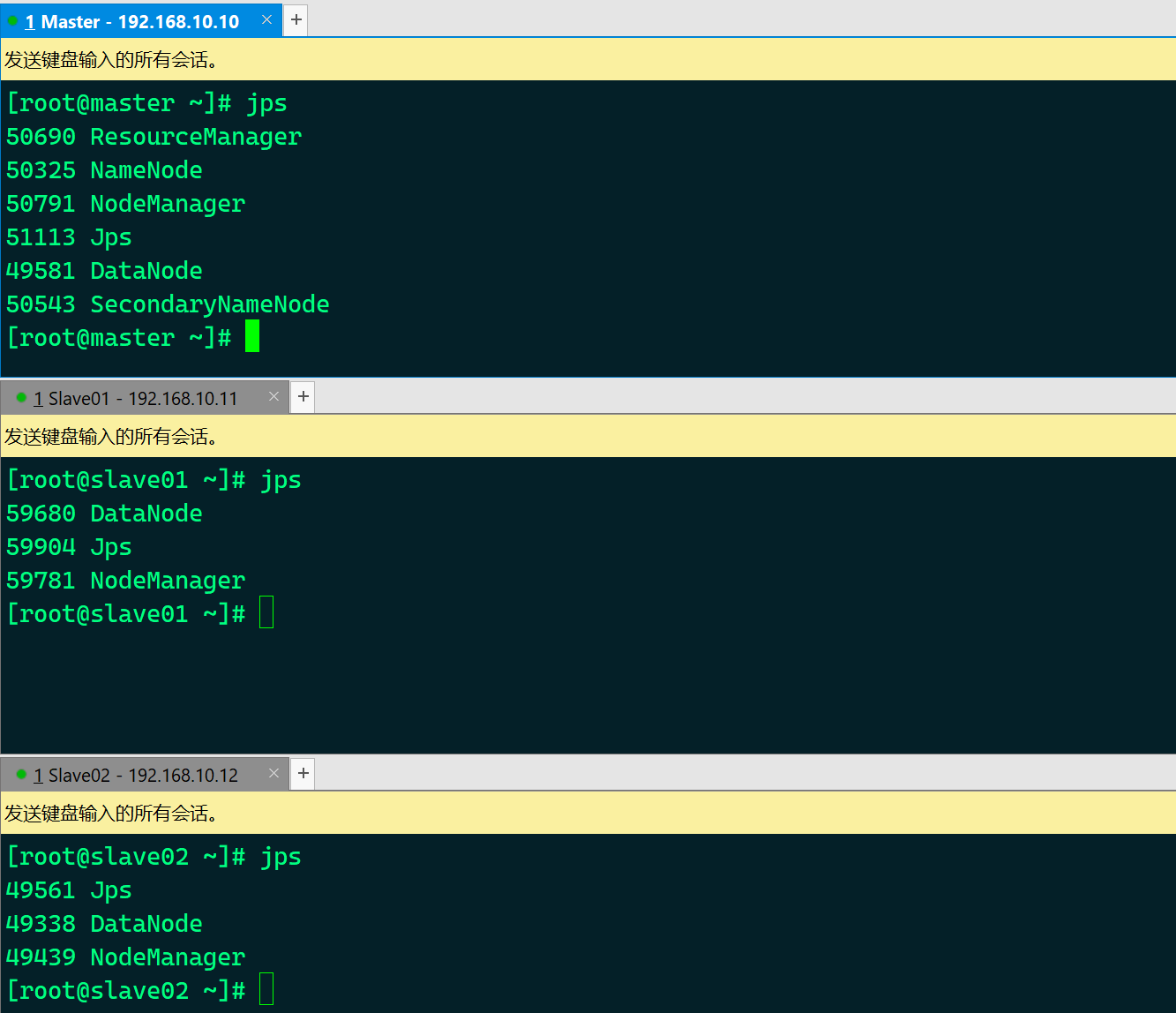
查看节点启动情况
# jps
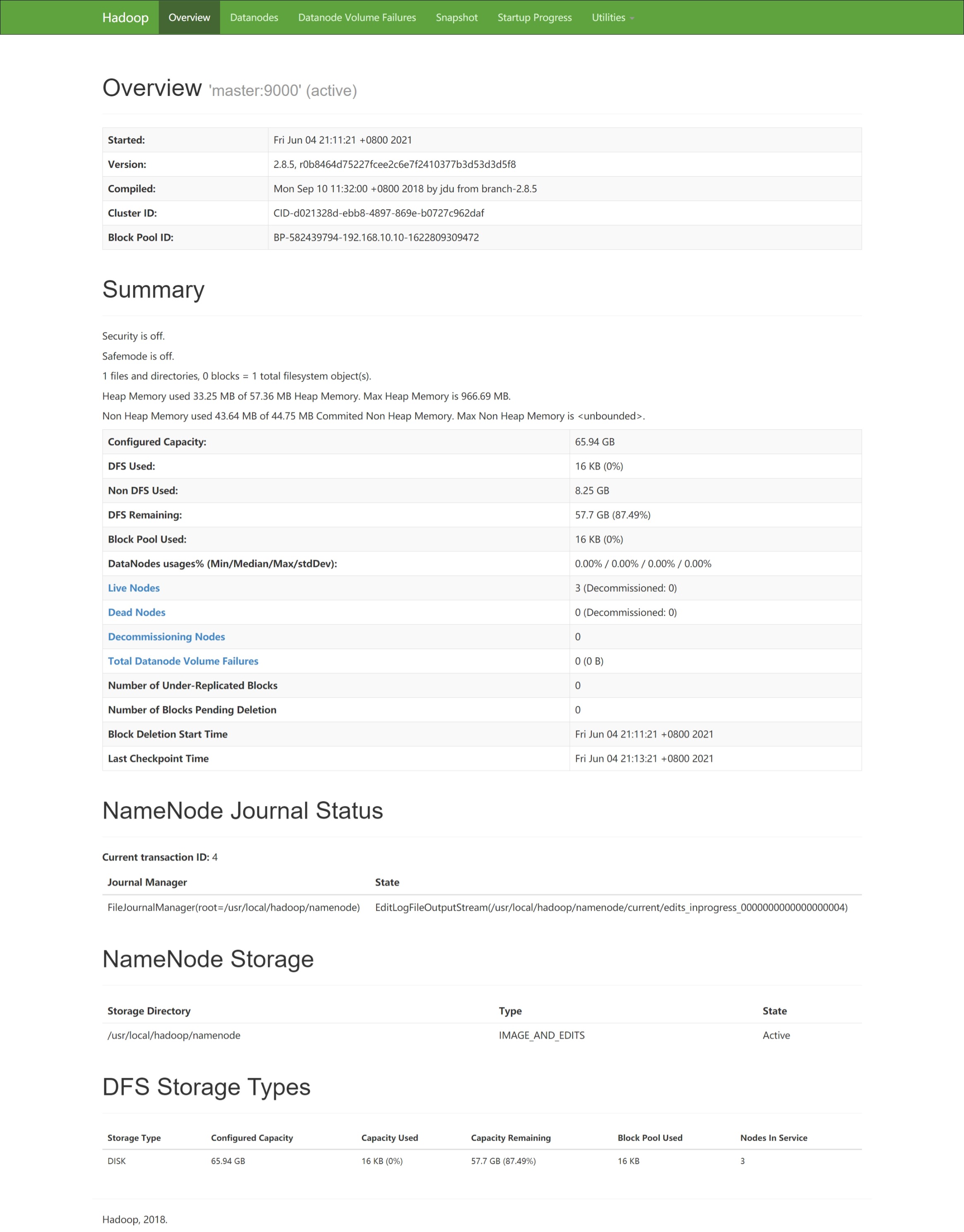
客户端查看集群信息
- 浏览器访问以下地址
master:50070
- 或
192.168.10.10:50070
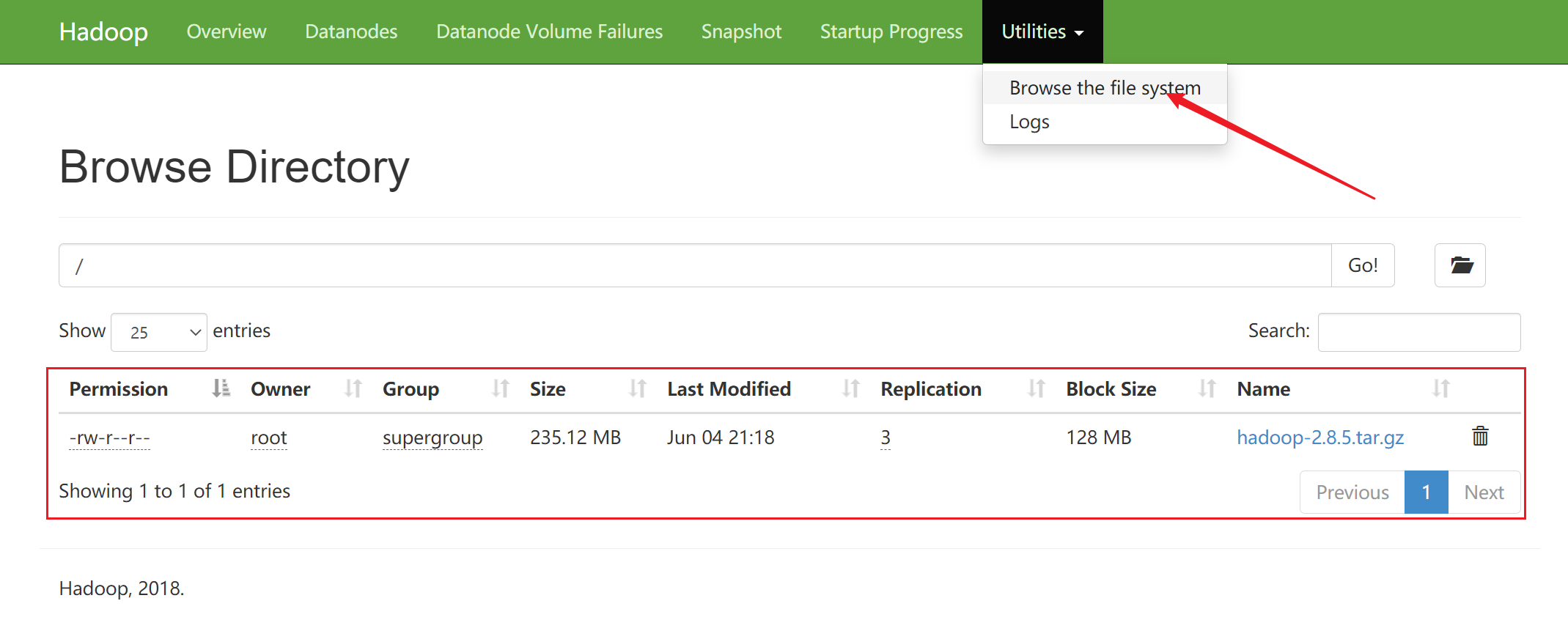
测试
- 上传文件
# hadoop fs -put <File> hdfs://master:9000/
例:
# hadoop fs -put hadoop-2.8.5.tar.gz hdfs://master:9000/

- 下载文件
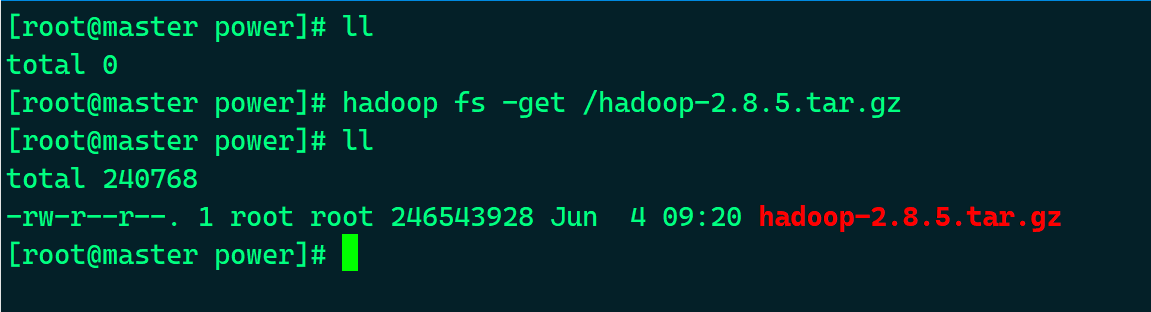
# hadoop fs -get / <File>
例:
# hadoop fs -get /hadoop-2.8.5.tar.gz
- 查看HDFS文件系统
# hadoop fs -ls /

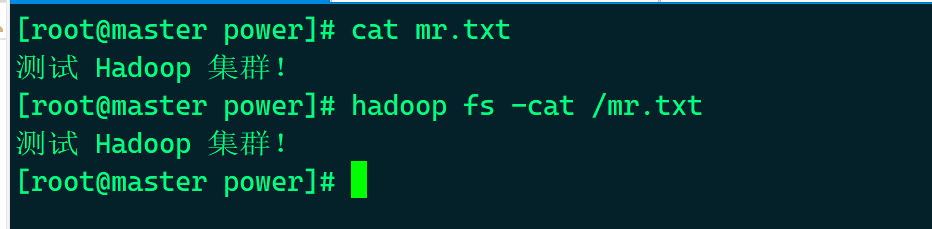
- 查看HDFS文件系统中的文本文件
# hadoop fs -cat / <File>
例:
# hadoop fs -cat /mr.txt
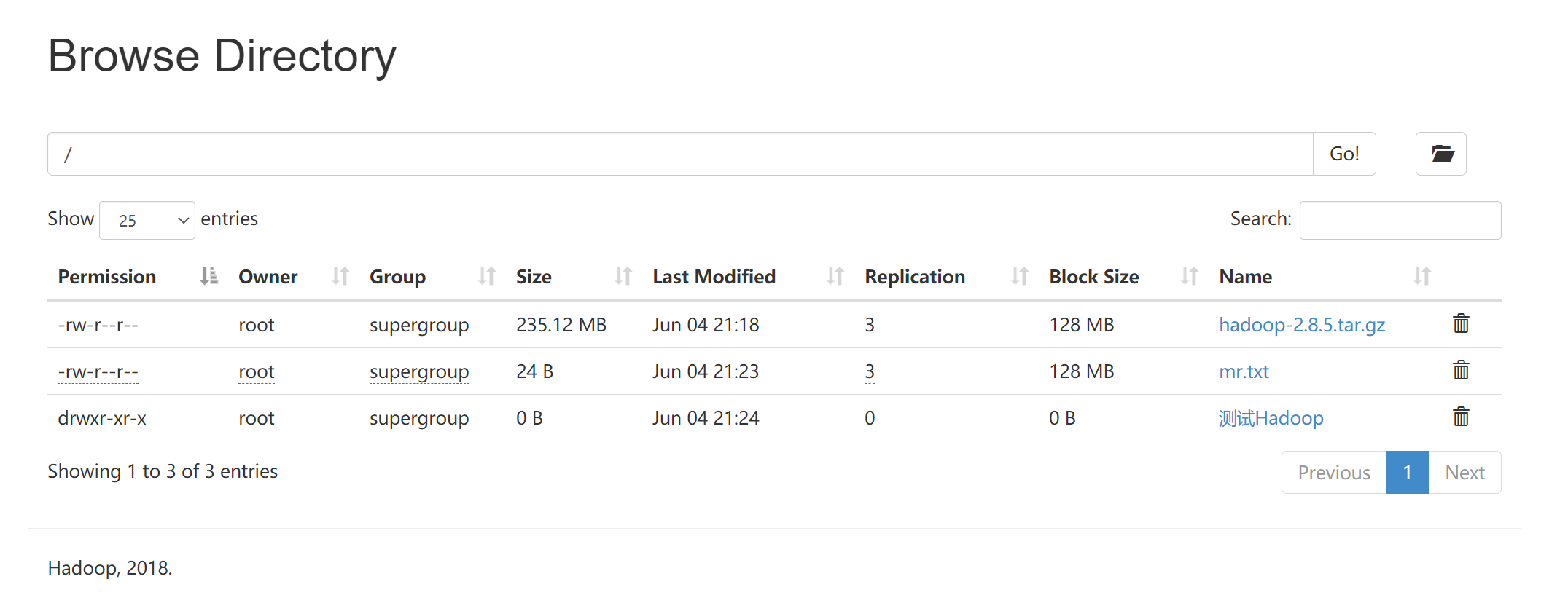
- 新建文件夹
# hadoop fs -mkdir /<Dir>
例:
# hadoop fs -mkdir /测试Hadoop

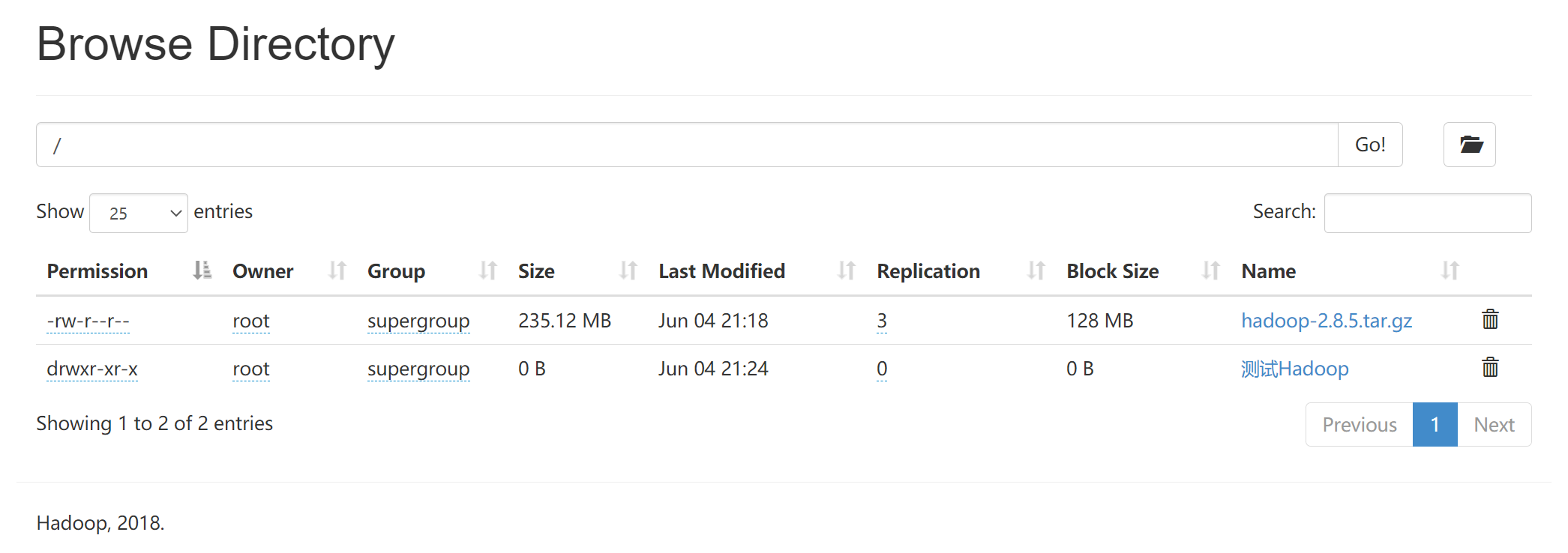
- 删除文件
# hdfs dfs -rm -r [文件地址]
例:
# hdfs dfs -rm -r /mr.txt

- 跳过回收站删除文件
# hdfs dfs -rm -skipTrash [文件地址]
例:
# hdfs dfs -rm -skipTrash /mr.txt

- 删除文件夹
# hdfs dfs -rm -r [文件夹地址]
例:
# hdfs dfs -rm -r /测试Hadoop

 评论
评论
0 评论




